SEO

Join 500+ brands growing with Passionfruit!
Have to start this one with a disclaimer and PSA : no one reallyyyy knows exactly how Google Search works - not even their own employees (and yes, I’ve spoken to a bunch of them). However, the recent Google documentation leaks, coupled with public documents from antitrust hearings has given us “outsiders” some really good insights that are relevant for anyone who’s in the space, or trying to rank on Google. This is my attempt at breaking down some of the complex processes into understandable, actionable snippets.
How does Google Search Work?
Indexing a new page
When you publish a new website, or page, Google does not immediately index it. Google must first become aware of the page. This can happen in couple different ways :
Submit a page via Google Search Console
Add it to you Sitemap / resubmit the Sitemap
Link the page from some other page so that Google’s crawler can find it the next time it crawls your website
While you should ideally do all, research has shown that new pages that are linked from popular pages (like home page, etc.) tend to get indexed faster.
Google has 5 different components involved in page discovery and the indexation process : the Trawler, Scheduler, Storeserver, Alexandria, and the (unconfirmed) Sandbox. The Trawler is responsible for retrieving new content. It is assisted by the Scheduler, which is responsible for telling the Trawler how often to revisit URLs to update the content. Once the Trawler has retrieved the content, it passes it onto the Storeserver. The Storeserver makes a decision as to whether the URL should be forwarded to Alexandria, or placed in the Sandbox.
Alexandria is Google’s codename for the indexing system - more on that later. What is very interesting (and also not confirmed by Google) is the existence of the Sandbox. The recent push towards monitoring spam and low quality content URLs has demanded the existence of this Sandbox : all low quality / spammy URLs are placed in the Sandbox as opposed to being sent to Alexandria. As Google is training its AI / ML models with reinforcement learning with human feedback, it seems very viable that they use this sandbox (pretty much as it sounds) as the test environment for figuring out if a page is “legit” or not.
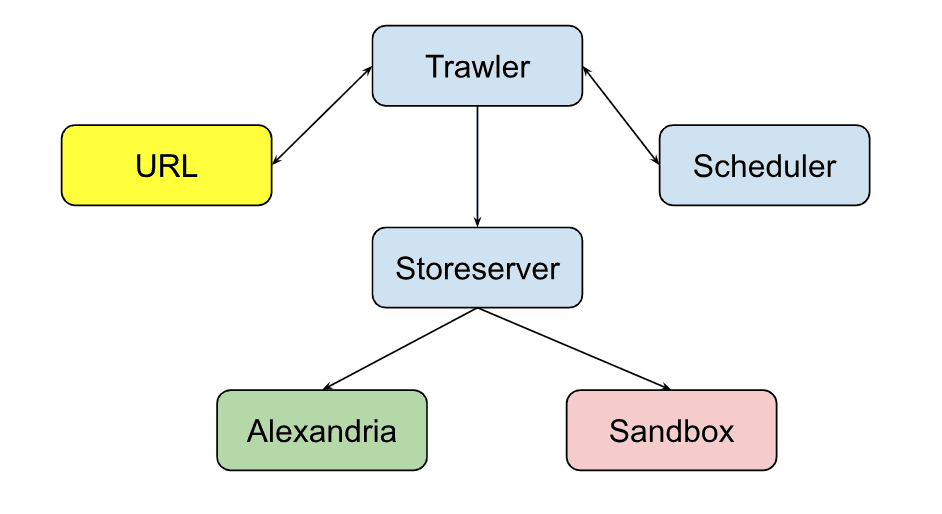
Google Search Indexing (Basic System Design)
Alexandria - Google’s Indexing System
Alexandria has been around for a while. While we can write several articles on just Alexandria, I’ll keep it short and touch on the points that actually matter for outsiders.
Alexandria stores documents, and each document contains one or more URLs. Why group URLs into documents? Because of duplicates, different URLs with the same content, the same content in different languages, hreflang implementations that cause minor differences in the URL, and so on and so forth. This list of documents is called Doc Index.
This is where the concept of Canonical URLs comes into play : each document should have one canonical url, which can be thought of as the “original”, most important URL of this group that Google will prioritize, index, and pass link equity to. Users can define canonicals themselves, but in the absence of a user declared canonicals, Google automatically decides which URL to make the canonical one.
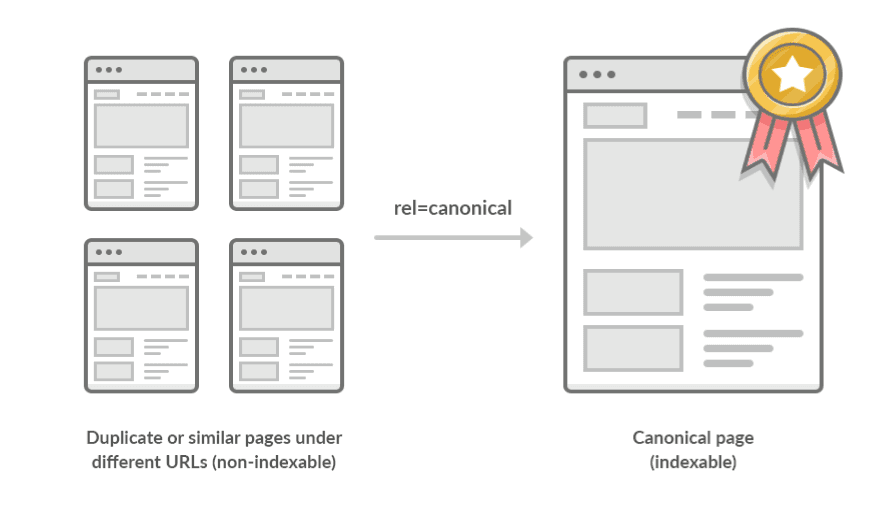
Canonical URLs Example
However, Alexandria doesn’t just store the Doc Index. It has 3 more components, the most important one being the Word Index. Each URL of every document is searched for top keyword phrases. These keyword phrases are stored in the Word Index, with links to the documents that are most relevant for these keyword phrases, along with an IR (Information Retrieval) score.
Query Based Salient Terms (QBST)
This is how Google Search is so fast : when you google something, Google does not go through all its documents. It looks at the phrase you searched for, finds the most relevant word / phrase in the Word Index (using QBST : Query Based Salient Terms), and shows the documents that have already been preprocessed and deemed relevant to that search phrase.
Now, there’s a lot more stuff that happens under the hood - from storing important data in HiveMind vs TeraGoogle, storing other metadata with documents in the Doc Index, etc. but that’s for another time. Let’s dive into how Google determines page relevancy, and how to rank well on Google.
Ascorer : creating the Green Ring
When you google something, we know that Alexandria uses the Word Index to find all relevant documents and URLs. However, this may be millions, if not billions, of URLs. Ascorer is a Google System that’s responsible for choosing the Top 1000 URLs (this is why you can see pages 1 - 100 on Google, with 10 URLs per page). The Top 1000 URLs are called the “Green Ring”.
Superroot : creating the Blue Ring
The Superroot is the Google System responsible for reducing the Green Ring to a list of Top 10 URLs : called the “Blue Ring”. If you’re trying to rank on Google, you know that you need to be on the first page : ideally even Top 5. You need to know how the Superroot system works, and how to optimize your pages to maximize your chances of ranking well here. Superroot has 2 different types of ranking algorithms that enables it to rank content so well: Twiddlers, and NavBoost. Let’s dive into those.
Twiddlers : Applying Google’s Ranking Factors
Think of twiddlers as independent content reviewers. Each twiddler looks at a URL, and gives it a score on a particular metric it is responsible for judging, for example page speed, domain age, meta titles, site authority, or the hundreds of other Google Ranking factors. Each twiddler gives a score that affects the rankings of a page. I’m assuming this is done by giving a multiplier score. For e.g. if something is good, add a multiplier of 1.2 (20% boost), or conversely, if something is slightly bad, add a multiplier of 0.9 (10% down). But given it’s commutative, it can probably be an addition too.
The beauty of this system is that it is so modular that all these twiddlers can work in parallel and apply hundreds of ranking factors almost instantly - since each one is independent, the scores can be added / multiplied in no particular order, whenever the individual twiddler is done assessing the page!
This is what I believe the majority of Google’s Search team works on : experimenting with new twiddlers, tweaking existing ones, or removing legacy ones. Once a twiddler is created, experimented with, and seen to improve the search experience, it is graduated into a Core Algorithm Update.
Twiddlers & Topicality
Twiddlers are also what enables Google to show topicality in content. For e.g. when you search “Football results” around the Superbowl, Google will show you American Football results. But if you search the same around the Euros, you’ll see “Soccer” results (even though this is real football 😀). This happens because Google has the ability to quickly release a Twiddler that up-scores relevant pages based on a particular topic / search results.
Another example is when Google wants to promote vetted content. For e.g. during COVID when you searched for tolls, you saw results from .gov websites come up first. This is because Google had released a Twiddler that promoted .gov websites to show verified data.
I’m sure there’ll be some other Twiddlers coming up as we near the elections this year.
NavBoost : Applying User Engagement Metrics
Google, at its core, serves the users. So irrespective of the hundreds of factors that Google uses to rank pages internally, it needs a way to incorporate actual user data / feedback into search. That’s where NavBoost comes in.
Although Google has officially denied user clicks for ranking purposes, FTC documents and documents from the recent hearing have confirmed that they’ve been using it since 2012!

Documents that show Google uses Clicks in Ranking Algorithms
I know that this opens up a lot of ethical concerns : does this breach data privacy laws? Without opening that can of worms today, I do understand why Google would want to use click data to feed into their ranking algorithms.
All their algorithms and twiddlers choose the Blue Ring / Top 10 results that clients see on the first page. But how do they know that it's good? Google can only verify the efficacy of their algorithms by learning from their users behaviors. And how do they learn from their users? By actually analyzing if people are clicking on the top results they show, or do they have to keep navigating to other pages. If they’re clicking, all is good : if they are not, then it means Google is not doing a good job at providing answers to questions.
Now, lets’ link this back to NavBoost. On average, the top organic position has a click through rate of 27%, and the second has a CTR of 15%. Let’s say Google decides to rank a new URL on these positions. If the CTR of the newly ranked URL is not in line with historic averages, then NavBoost looks at the discrepancy and accordingly promotes or demotes the ranking : if the CTR is too low (let’s say 5% in position 2 vs. expected 15%), NavBoost will demote the URL so that it ranks lower. Conversely, if click through rate is higher than 10%, then there’s a high chance that your content will be ranked in Top 3 organic positions!
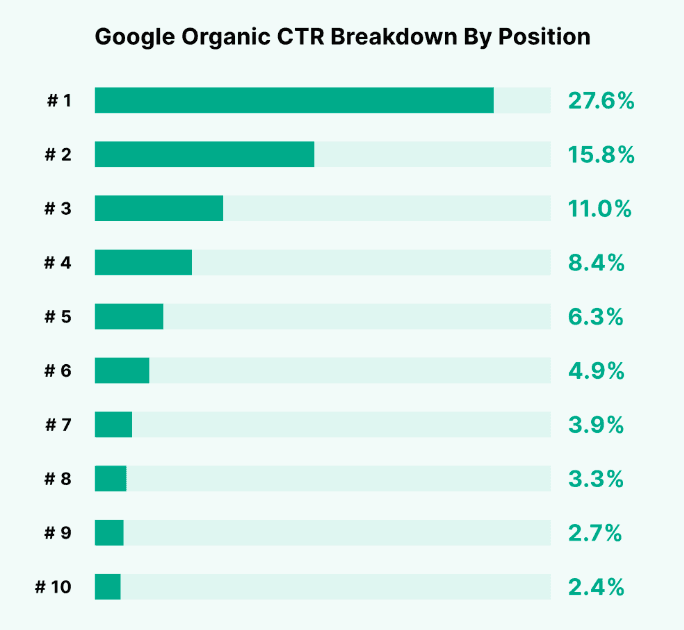
Average click through rate by position on Google
How to Rank Well on Google
This is the million, or rather, billion dollar question. The truth is that it’s not one thing, or an exact set of things that will enable you to be the top dog for a search query. However, there are some actions that you can take to maximize your chances to be in Position 1, and at the very least, puts you in a good spot to be in the Blue Ring.
Ensure that your page is indexed
This seems obvious, but you’ll be surprised to see how many of your pages are actually not indexed. This is especially important for E-Commerce companies who have hundreds of pages for different SKUs, products, variants, etc. You can check your Indexing Report on Google Search Console, and submit Indexing Requests from there. If you’re tech enabled, you can programmatically submit thousands of indexing and reindexing requests in one go using Google APIs (that’s what we do at Passionfruit for all our clients).
Optimize your SEO Meta Tags
For those who don’t know, SEO Meta Tags (Title and Description) are what appear on Google / other search engines when your link is shown to them). Optimal meta tags increase your Click Through Rate. As is evident from NavBoost and general user behavior, high click through rates enable you to rank better, because it is a strong signal that people are interested in learning about your product / service / company!
Improve User Experience
Several Twiddlers are focused on assessing a website user experience : from page speed, accessibility, structure, pop ups, and so on and so forth. Better user experience means these Twiddlers promote your website. It also means that users will engage with your website more, which in turn will create a positive flywheel for ranking.
Improve User Engagement
NavBoost is rumored to look at not just clicks, but also other user engagement metrics like time spent, percent scrolled, etc. It’s not just about getting users to visit your website : it’s about creating websites and content that is engaging and keeps users on your website.
Account for Search Intent
A core part of Google QBST algorithm is not just finding semantic matches of relevant words, but understanding why someone is searching something : is it to purchase (commercial / transactional), find (navigational), or learn (informational)? The keywords and topics you target on pages must be aligned with a user’s intent. For e.g. for E-Commerce companies, your product pages should be geared towards commercial / transactional keywords, while blogs and FAQ pages should be geared towards informational ones.
Re-optimize Content
It’s not just about churning out new content. Look at what content pieces are doing well, and reoptimize those. One of Google’s Twiddlers measures ContentEffortScore that keeps track of how much effort goes into a particular content piece.
Target Long Tail & Zero Volume Keywords
Yes, we know you want to rank well for phrases that are searched a lot. However, the truth of the matter is that ranking for those will take a while, especially if you’re a newer business or competing with folks who’ve been established and been leaders for decades. That does not mean it is not possible. Your strategy must be different. Target related, longer tail keywords that will allow you to rank well on those faster. At the same time, that will help you build Topical Authority and at least show up in Google’s Word Index for your ideal keywords. This coupled with some good user engagement metrics will enable you to be in the Blue Ring faster than expected.





